
29 Feb
2008
29 Feb
'08
1:32 p.m.
Hello
I guess that is a common problem when imputing data, but I am rather
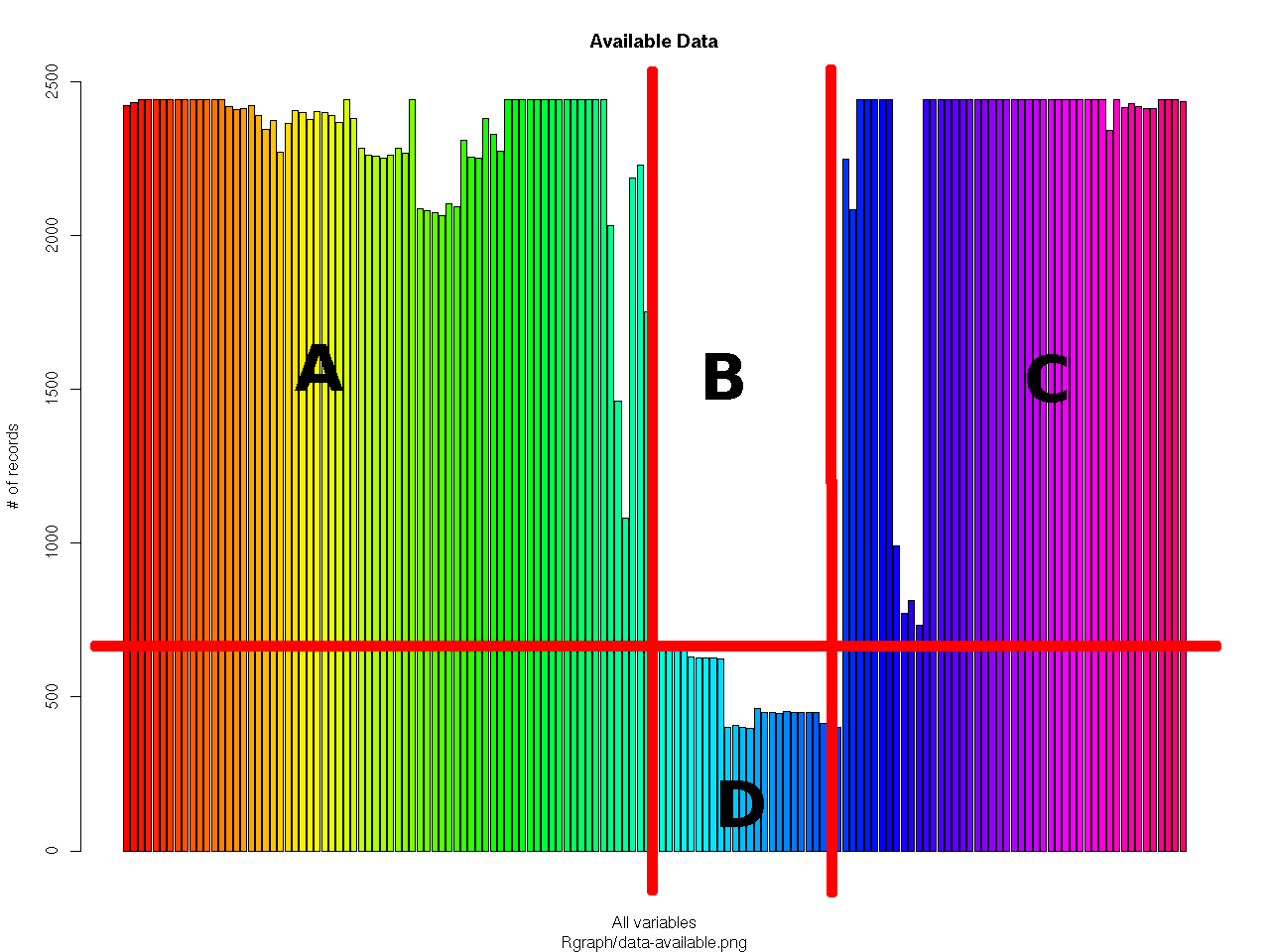
confused by it. The availability (= not-NA-ness) of my survey data looks
like this (-> screenshot). It shows the number of non-NA entries for each
variable in the data frame.
Areas A and C have rather complete answer sets. B is white because these
questions have only been asked conditional on answers given beforehand
(in A). But a part of the white area (in D) -could- be imputed.
How does the imputation process look like? What to do with B? I could
think of two variants that are both more or less unclear to me:
A) Should I cut the dataframe and impute in two steps? But how do I then
reintegrate the results from the first imputation?
i) remove B+D, impute A+C
ii) reinsert B/D and impute D.
B) How do I specify the process for one MI step without cutting?
Thank you very much for your thoughts on this.
Best regards,
Marcus
--
Marcus M. Dapp | PhD student | ETH Zurich | www.ib.ethz.ch/people/mdapp
Prof. Thomas Bernauer, International Relations | www.ib.ethz.ch
On the shoulders of giants? http://science.creativecommons.org
{kind=link}
5905
days inactive
5905
days old
amelia@lists.gking.harvard.edu
0 comments
1 participants
participants (1)
-
 Marcus M. Dapp
Marcus M. Dapp