
22 Jun
2017
22 Jun
'17
5:24 p.m.
Hi, I’m new to using Amelia. I’m trying to impute missing data for a time-series
cross-sectional data, but I'm having trouble running amelia() the way I think I
should. I would greatly appreciate some guidance.
I created a data.frame() that has 8 time points each for 260 participants and a single
score column for which I’m trying to impute some missing data. The data frame has 2080
(i.e., 8*260) rows by 3 columns (“month”, “ID”, “score”).
With this, I tried to run the following command:
```
a.out <- amelia(data, ts="month", cs="ID", polytime=2,
intercs=TRUE, p2s=2)
```
It reported (which I terminated part way through after receiving errors):
amelia starting
beginning prep functions
Variables used: score time.1 time.2 time.3 time.4 time.5 time.6 time.7 time.8 time.9
time.10 time.11 time.12 time.13 time.14 time.15 time.16 time.17 time.18 time.19 time.20
time.21 time.22 time.23 time.24 time.25 time.26 time.27 time.28 time.29 time.30 time.31
time.32 time.33 time.34 time.35 time.36 time.37 time.38 time.39 time.40 time.41 time.42
time.43 time.44 time.45 time.46 time.47 time.48 time.49 time.50 time.51 time.52 time.53
time.54 time.55 time.56 time.57 time.58 time.59 time.60 time.61 time.62 time.63 time.64
time.65 time.66 time.67 time.68 time.69 time.70 time.71 time.72 time.73 time.74 time.75
time.76 time.77 time.78 time.79 time.80 time.81 time.82 time.83 time.84 time.85 time.86
time.87 time.88 time.89 time.90 time.91 time.92 time.93 time.94 time.95 time.96 time.97
time.98 time.99 time.100 time.101 time.102 time.103 time.104 time.105 time.106 time.107
time.108 time.109 time.110 time.111 time.112 time.113 time.114 time.115 time.116 time.117
time.118 time.119 time.120 time.... <truncated>
running bootstrap
-- Imputation 1 --
setting up EM chain indicies
1(300713)! 2
error: inv_sympd(): matrix seems singular
(216)! 3
error: inv_sympd(): matrix seems singular
(208)!
Warning message:
In amelia.prep(x = x, m = m, idvars = idvars, empri = empri, ts = ts, :
You have a small number of observations, relative to the number, of variables in the
imputation model. Consider removing some variables, or reducing the order of time
polynomials to reduce the number of parameters.
I don’t understand the error. I also don’t understand how it determined the `time.x`
variables—I know it has something to do with my number of participants but I don’t
understand how. The warning message suggests I have too many variables because of this.
When I tried using the “freetrade" dataset, it used way fewer `time.x` variables
(i.e., 26) even though there were only 19 time points in the data set and didn’t have
problems.
Could someone explain to me about the error or what may be the problem and what I should
do to correct it?
Also, when using time series data, do I use amelia() differently whether the time variable
is treated as chronological time (e.g., January, February, March, …) or time of onset
(e.g., one month since birth, two months since birth, etc.)?
Please advise.
Best regards,
Lawrence

23 Jun
23 Jun
10:07 p.m.
Hi Lawrence,
What's happening here is that "polytime = 2" adds a "time" and
"time^2" as
additional regressors to the imputation matrix. Then, "intercs = TRUE" adds
a dummy variable for each cross-sectional unit *and then interacts the two
time variables with each dummy variable*. Thus, if you have 260
participants x 2 time variables, that's 520 variables that you're adding to
the imputation matrix. The idea behind what you are doing is to capture
participant-specific time trends, but there appears to not be enough data
per respondent to estimate these trends well. Thus, you could probably fix
the problem by estimating a global time trend with "intercs = FALSE".
Hope that helps!
Cheers,
Matt
~~~~~~~~~~~
Matthew Blackwell
Assistant Professor of Government
Harvard University
url: http://www.mattblackwell.org
On Thu, Jun 22, 2017 at 5:24 PM, Lawrence Chen <
lawrence.m.chen(a)mail.mcgill.ca> wrote:
Hi, I’m new to using Amelia. I’m trying to impute
missing data for a
time-series cross-sectional data, but I'm having trouble running amelia()
the way I think I should. I would greatly appreciate some guidance.
I created a data.frame() that has 8 time points each for 260 participants
and a single score column for which I’m trying to impute some missing data.
The data frame has 2080 (i.e., 8*260) rows by 3 columns (“month”, “ID”,
“score”).
With this, I tried to run the following command:
```
a.out <- amelia(data, ts="month", cs="ID", polytime=2,
intercs=TRUE, p2s=2)
```
It reported (which I terminated part way through after receiving errors):
amelia starting
beginning prep functions
Variables used: score time.1 time.2 time.3 time.4 time.5 time.6 time.7
time.8 time.9 time.10 time.11 time.12 time.13 time.14 time.15 time.16
time.17 time.18 time.19 time.20 time.21 time.22 time.23 time.24 time.25
time.26 time.27 time.28 time.29 time.30 time.31 time.32 time.33 time.34
time.35 time.36 time.37 time.38 time.39 time.40 time.41 time.42 time.43
time.44 time.45 time.46 time.47 time.48 time.49 time.50 time.51 time.52
time.53 time.54 time.55 time.56 time.57 time.58 time.59 time.60 time.61
time.62 time.63 time.64 time.65 time.66 time.67 time.68 time.69 time.70
time.71 time.72 time.73 time.74 time.75 time.76 time.77 time.78 time.79
time.80 time.81 time.82 time.83 time.84 time.85 time.86 time.87 time.88
time.89 time.90 time.91 time.92 time.93 time.94 time.95 time.96 time.97
time.98 time.99 time.100 time.101 time.102 time.103 time.104 time.105
time.106 time.107 time.108 time.109 time.110 time.111 time.112 time.113
time.114 time.115 time.116 time.117 time.118 time.119 time.120 time....
<truncated>
running bootstrap
-- Imputation 1 --
setting up EM chain indicies
1(300713)! 2
error: inv_sympd(): matrix seems singular
(216)! 3
error: inv_sympd(): matrix seems singular
(208)!
Warning message:
In amelia.prep(x = x, m = m, idvars = idvars, empri = empri, ts = ts, :
You have a small number of observations, relative to the number, of
variables in the imputation model. Consider removing some variables, or
reducing the order of time polynomials to reduce the number of parameters.
I don’t understand the error. I also don’t understand how it determined
the `time.x` variables—I know it has something to do with my number of
participants but I don’t understand how. The warning message suggests I
have too many variables because of this. When I tried using the “freetrade"
dataset, it used way fewer `time.x` variables (i.e., 26) even though there
were only 19 time points in the data set and didn’t have problems.
Could someone explain to me about the error or what may be the problem and
what I should do to correct it?
Also, when using time series data, do I use amelia() differently whether
the time variable is treated as chronological time (e.g., January,
February, March, …) or time of onset (e.g., one month since birth, two
months since birth, etc.)?
Please advise.
Best regards,
Lawrence
--
Amelia mailing list served by HUIT
[Un]Subscribe/View Archive: http://lists.gking.harvard.edu/?info=amelia
More info about Amelia: http://gking.harvard.edu/amelia
Amelia mailing list
Amelia(a)lists.gking.harvard.edu
To unsubscribe from this list or get other information:
https://lists.gking.harvard.edu/mailman/listinfo/amelia
26 Jun
26 Jun
8:47 a.m.
Hi Matt,
Thank you for your suggestion and clarification on how I got that many time variables.
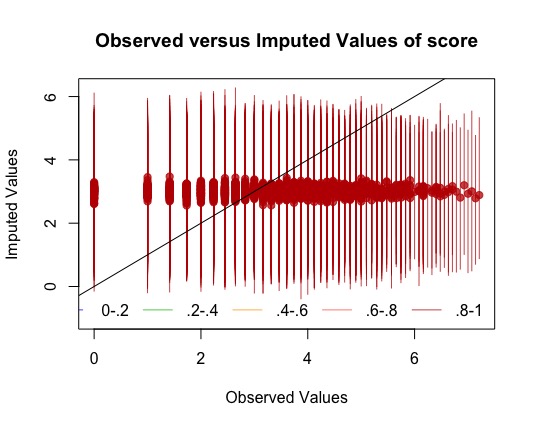
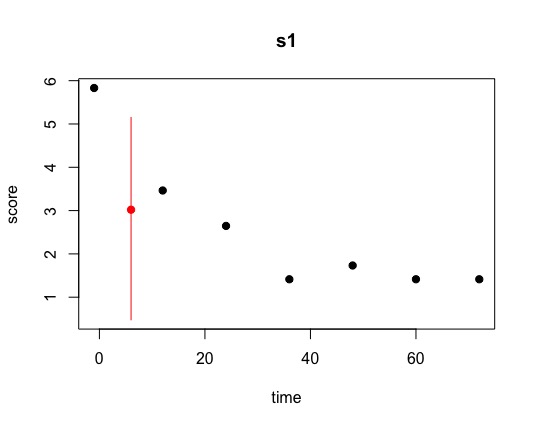
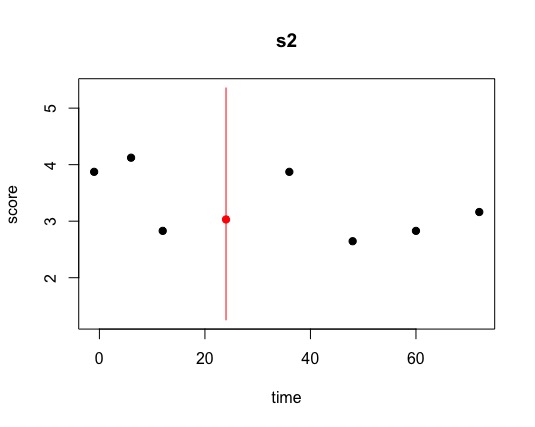
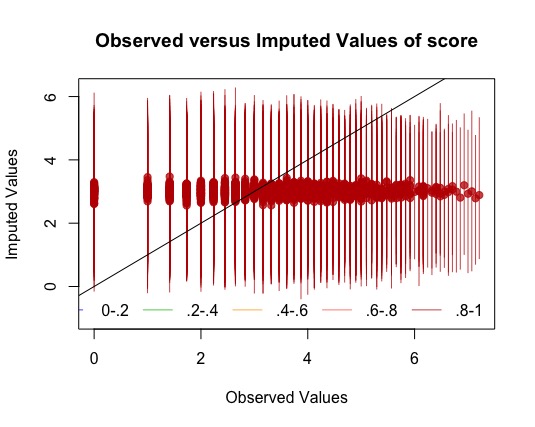
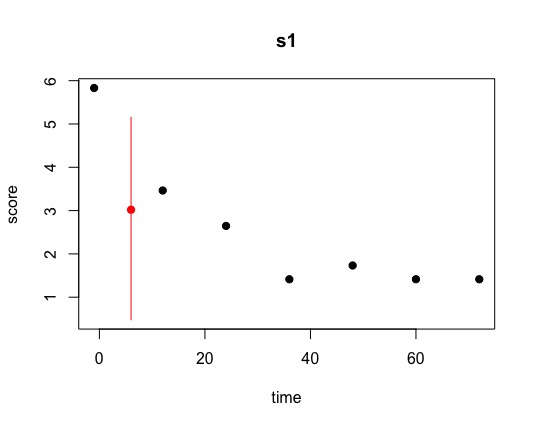
However, when I set "intercs=FALSE”, amelia appeared to impute my data poorly, as
seen in the attached images of the overimpute plot and a couple of samples of the
tscsPlots. I also tried with lags and leads, but the overimpute plot also showed that it
had poor accuracy. In contrast, when I explored imputing only few participants at a time
(e.g., n=5) with “intercs=TRUE”, amelia seemed to do a good job with the imputation,
indicated by having short 95% bands and usually good alignment of the points in the
overimpute plot. Do you think it would be appropriate to select five participants randomly
at a time (i.e., 260 participants / 5 = 52 times) to run amelia? However, this approach
may be scrutinized for not imputing using all study’s participants together though. What
would you suggest?
[cid:06083E65-E672-4A0E-B0CA-8036D7108D58][cid:59E67800-05A8-4BCB-B1D5-288B7C0A60A1][cid:935C3DB0-E3EE-4B1C-9EF1-317C04700D53]
Best regards,
Lawrence
On Jun 23, 2017, at 10:07 PM, Matt Blackwell
<mblackwell@gov.harvard.edu<mailto:mblackwell@gov.harvard.edu>> wrote:
Hi Lawrence,
What's happening here is that "polytime = 2" adds a "time" and
"time^2" as additional regressors to the imputation matrix. Then, "intercs
= TRUE" adds a dummy variable for each cross-sectional unit *and then interacts the
two time variables with each dummy variable*. Thus, if you have 260 participants x 2 time
variables, that's 520 variables that you're adding to the imputation matrix. The
idea behind what you are doing is to capture participant-specific time trends, but there
appears to not be enough data per respondent to estimate these trends well. Thus, you
could probably fix the problem by estimating a global time trend with "intercs =
FALSE".
Hope that helps!
Cheers,
Matt
~~~~~~~~~~~
Matthew Blackwell
Assistant Professor of Government
Harvard University
url: http://www.mattblackwell.org<http://www.mattblackwell.org/>
On Thu, Jun 22, 2017 at 5:24 PM, Lawrence Chen
<lawrence.m.chen@mail.mcgill.ca<mailto:lawrence.m.chen@mail.mcgill.ca>>
wrote:
Hi, I’m new to using Amelia. I’m trying to impute missing data for a time-series
cross-sectional data, but I'm having trouble running amelia() the way I think I
should. I would greatly appreciate some guidance.
I created a data.frame() that has 8 time points each for 260 participants and a single
score column for which I’m trying to impute some missing data. The data frame has 2080
(i.e., 8*260) rows by 3 columns (“month”, “ID”, “score”).
With this, I tried to run the following command:
```
a.out <- amelia(data, ts="month", cs="ID", polytime=2,
intercs=TRUE, p2s=2)
```
It reported (which I terminated part way through after receiving errors):
amelia starting
beginning prep functions
Variables used: score time.1 time.2 time.3 time.4 time.5 time.6 time.7 time.8 time.9
time.10 time.11 time.12 time.13 time.14 time.15 time.16 time.17 time.18 time.19 time.20
time.21 time.22 time.23 time.24 time.25 time.26 time.27 time.28 time.29 time.30 time.31
time.32 time.33 time.34 time.35 time.36 time.37 time.38 time.39 time.40 time.41 time.42
time.43 time.44 time.45 time.46 time.47 time.48 time.49 time.50 time.51 time.52 time.53
time.54 time.55 time.56 time.57 time.58 time.59 time.60 time.61 time.62 time.63 time.64
time.65 time.66 time.67 time.68 time.69 time.70 time.71 time.72 time.73 time.74 time.75
time.76 time.77 time.78 time.79 time.80 time.81 time.82 time.83 time.84 time.85 time.86
time.87 time.88 time.89 time.90 time.91 time.92 time.93 time.94 time.95 time.96 time.97
time.98 time.99 time.100 time.101 time.102 time.103 time.104 time.105 time.106 time.107
time.108 time.109 time.110 time.111 time.112 time.113 time.114 time.115 time.116 time.117
time.118 time.119 time.120 time.... <truncated>
running bootstrap
-- Imputation 1 --
setting up EM chain indicies
1(300713)! 2
error: inv_sympd(): matrix seems singular
(216)! 3
error: inv_sympd(): matrix seems singular
(208)!
Warning message:
In amelia.prep(x = x, m = m, idvars = idvars, empri = empri, ts = ts, :
You have a small number of observations, relative to the number, of variables in the
imputation model. Consider removing some variables, or reducing the order of time
polynomials to reduce the number of parameters.
I don’t understand the error. I also don’t understand how it determined the `time.x`
variables—I know it has something to do with my number of participants but I don’t
understand how. The warning message suggests I have too many variables because of this.
When I tried using the “freetrade" dataset, it used way fewer `time.x` variables
(i.e., 26) even though there were only 19 time points in the data set and didn’t have
problems.
Could someone explain to me about the error or what may be the problem and what I should
do to correct it?
Also, when using time series data, do I use amelia() differently whether the time variable
is treated as chronological time (e.g., January, February, March, …) or time of onset
(e.g., one month since birth, two months since birth, etc.)?
Please advise.
Best regards,
Lawrence
--
Amelia mailing list served by HUIT
[Un]Subscribe/View Archive: http://lists.gking.harvard.edu/?info=amelia
More info about Amelia: http://gking.harvard.edu/amelia
Amelia mailing list
Amelia@lists.gking.harvard.edu<mailto:Amelia@lists.gking.harvard.edu>
To unsubscribe from this list or get other information:
https://lists.gking.harvard.edu/mailman/listinfo/amelia
{kind=link}
{kind=link}
{kind=link}
6 Jul
6 Jul
8:41 p.m.
Hi Lawrence,
Hm, if it's the case that you can impute with intercs=TRUE for a subset of
observations, it might be the case that there are units in the data whose
data values are collinear with time, leading to the errors that you saw in
the original post. You might try to figure out which observations those are
by, say, running amelia with progressively larger subsets of units until
you hit the one (or more) that is (are) causing problems. Then, you can
drop those units and impute just the ones with some information. My (wild)
guess is that there might be some units for which there is no data or one 1
or 2 data points over time. This would cause problems when you try to
estimate a polynomial trend.
Hope that helps!
Cheers,
Matt
~~~~~~~~~~~
Matthew Blackwell
Assistant Professor of Government
Harvard University
url: http://www.mattblackwell.org
On Mon, Jun 26, 2017 at 8:47 AM, Lawrence Chen <
lawrence.m.chen(a)mail.mcgill.ca> wrote:
Hi Matt,
Thank you for your suggestion and clarification on how I got that many
time variables.
However, when I set "intercs=FALSE”, amelia appeared to impute my data
poorly, as seen in the attached images of the overimpute plot and a couple
of samples of the tscsPlots. I also tried with lags and leads, but the
overimpute plot also showed that it had poor accuracy. In contrast, when I
explored imputing only few participants at a time (e.g., n=5) with
“intercs=TRUE”, amelia seemed to do a good job with the imputation,
indicated by having short 95% bands and usually good alignment of the
points in the overimpute plot. Do you think it would be appropriate to
select five participants randomly at a time (i.e., 260 participants / 5 =
52 times) to run amelia? However, this approach may be scrutinized for not
imputing using all study’s participants together though. What would you
suggest?
Best regards,
Lawrence
On Jun 23, 2017, at 10:07 PM, Matt Blackwell <mblackwell(a)gov.harvard.edu>
wrote:
Hi Lawrence,
What's happening here is that "polytime = 2" adds a "time" and
"time^2" as
additional regressors to the imputation matrix. Then, "intercs = TRUE" adds
a dummy variable for each cross-sectional unit *and then interacts the two
time variables with each dummy variable*. Thus, if you have 260
participants x 2 time variables, that's 520 variables that you're adding to
the imputation matrix. The idea behind what you are doing is to capture
participant-specific time trends, but there appears to not be enough data
per respondent to estimate these trends well. Thus, you could probably fix
the problem by estimating a global time trend with "intercs = FALSE".
Hope that helps!
Cheers,
Matt
~~~~~~~~~~~
Matthew Blackwell
Assistant Professor of Government
Harvard University
url: http://www.mattblackwell.org
<https://urldefense.proofpoint.com/v2/url?u=http-3A__www.mattblackwell.org_&d=DwMGaQ&c=WO-RGvefibhHBZq3fL85hQ&r=EwICq0J5pL8CwgEJz8qkmauGonk0XmiLpxcYOEgk2a0&m=QKalnxThgSj95M1uR0ZDKRLjbV4AQ7pzjbuks_CNtk4&s=hMNiGRlansRY1isu0Hqq5gHK05Ov5oIPSujTmCS2RD8&e=>
On Thu, Jun 22, 2017 at 5:24 PM, Lawrence Chen <
lawrence.m.chen(a)mail.mcgill.ca> wrote:
Hi, I’m new to using Amelia. I’m trying to impute
missing data for a
time-series cross-sectional data, but I'm having trouble running amelia()
the way I think I should. I would greatly appreciate some guidance.
I created a data.frame() that has 8 time points each for 260 participants
and a single score column for which I’m trying to impute some missing data.
The data frame has 2080 (i.e., 8*260) rows by 3 columns (“month”, “ID”,
“score”).
With this, I tried to run the following command:
```
a.out <- amelia(data, ts="month", cs="ID", polytime=2,
intercs=TRUE,
p2s=2)
```
It reported (which I terminated part way through after receiving errors):
amelia starting
beginning prep functions
Variables used: score time.1 time.2 time.3 time.4 time.5 time.6 time.7
time.8 time.9 time.10 time.11 time.12 time.13 time.14 time.15 time.16
time.17 time.18 time.19 time.20 time.21 time.22 time.23 time.24 time.25
time.26 time.27 time.28 time.29 time.30 time.31 time.32 time.33 time.34
time.35 time.36 time.37 time.38 time.39 time.40 time.41 time.42 time.43
time.44 time.45 time.46 time.47 time.48 time.49 time.50 time.51 time.52
time.53 time.54 time.55 time.56 time.57 time.58 time.59 time.60 time.61
time.62 time.63 time.64 time.65 time.66 time.67 time.68 time.69 time.70
time.71 time.72 time.73 time.74 time.75 time.76 time.77 time.78 time.79
time.80 time.81 time.82 time.83 time.84 time.85 time.86 time.87 time.88
time.89 time.90 time.91 time.92 time.93 time.94 time.95 time.96 time.97
time.98 time.99 time.100 time.101 time.102 time.103 time.104 time.105
time.106 time.107 time.108 time.109 time.110 time.111 time.112 time.113
time.114 time.115 time.116 time.117 time.118 time.119 time.120 time....
<truncated>
running bootstrap
-- Imputation 1 --
setting up EM chain indicies
1(300713)! 2
error: inv_sympd(): matrix seems singular
(216)! 3
error: inv_sympd(): matrix seems singular
(208)!
Warning message:
In amelia.prep(x = x, m = m, idvars = idvars, empri = empri, ts = ts, :
You have a small number of observations, relative to the number, of
variables in the imputation model. Consider removing some variables, or
reducing the order of time polynomials to reduce the number of parameters.
I don’t understand the error. I also don’t understand how it determined
the `time.x` variables—I know it has something to do with my number of
participants but I don’t understand how. The warning message suggests I
have too many variables because of this. When I tried using the “freetrade"
dataset, it used way fewer `time.x` variables (i.e., 26) even though there
were only 19 time points in the data set and didn’t have problems.
Could someone explain to me about the error or what may be the problem
and what I should do to correct it?
Also, when using time series data, do I use amelia() differently whether
the time variable is treated as chronological time (e.g., January,
February, March, …) or time of onset (e.g., one month since birth, two
months since birth, etc.)?
Please advise.
Best regards,
Lawrence
--
Amelia mailing list served by HUIT
[Un]Subscribe/View Archive: http://lists.gking.harvard.edu/?info=amelia
More info about Amelia: http://gking.harvard.edu/amelia
Amelia mailing list
Amelia(a)lists.gking.harvard.edu
To unsubscribe from this list or get other information:
https://lists.gking.harvard.edu/mailman/listinfo/amelia
{kind=link}
{kind=link}
{kind=link}
2491
days inactive
2506
days old
amelia@lists.gking.harvard.edu
3 comments
2 participants
participants (2)
-
 Lawrence Chen
Lawrence Chen -
 Matt Blackwell
Matt Blackwell