
8 Apr
2011
8 Apr
'11
8:47 a.m.
Dear all,
I'm currently using amelia to impute income in cross-sectional data
(about 30% are missing). The distribution of the available income data
is right skewed, so I transformed the income using the natural
logarithm. Unfortunately the income data is also top-coded or
right-censored - that is all respondents with an income above a certain
limit are summarized into one category. (see example in the following
paper, dealing exactly with this problem:
http://www.fcsm.gov/07papers/Buettner.X-C.pdf)
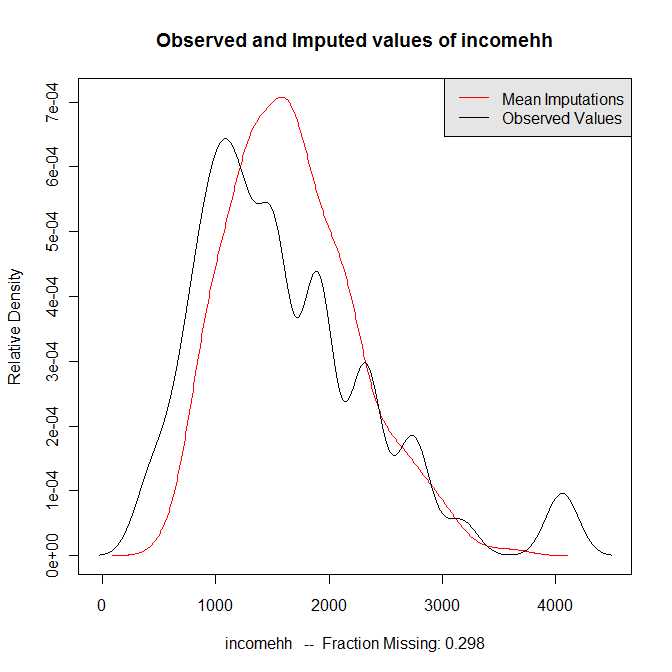
Comparison of observed and imputed data
(I've also added the comparison of imputed and observed data in a
jpeg-file where the imputation worked and I hope that the graph is visible)
So I have two problems:
1.) In some of the data sets, when there are a lot of people in the top
category the imputation is not succesfull at all.
2.) But even if the imputation is working, the imputed values in the
upper categories are smaller than the observed values - and only very
few imputed values are above the maximum of the observed values.
Is there any way to deal with these problems in Amelia? Or do I have to
transform the income data to get a good imputation?
Thanks for your help,
Elias
--
Elias Naumann
SFB 884
Universität Mannheim
{kind=link}